The next blog post introduces a Terraform module to automate the steps explained here!
In the ever-evolving landscape of cloud computing, optimizing data workflows is paramount for achieving efficiency and scalability. Even though Google Cloud Platform offers the powerful Dataflow service to process data at scale, sometimes the simplest solution is worth a shot.
In cases with a relatively high Pub/Sub volume (>10 messages per second), a pull subscription with a continuously running worker is more cost-efficient and quicker than a push subscription. Using a combination of Docker, Instance Templates and Instance Groups, it is pretty simple to set up an auto-scaling group of instances that will process Pub/Sub messages.
This guide will walk you through the process of configuring GCP infrastructure that efficiently pulls JSON messages from a Pub/Sub subscription, infers schema, and inserts them directly into a Cloud SQL PostgreSQL database using micro-batch processing.
Never miss a new post
The issue at hand
In my current role at WishRoll, I was faced with the issue of processing a high amount of events and store them in the production database directly.
Imagine the scene: the server application produces analytics-style events such as "user logged-in", and "task X was completed" (among others). Eventually, for example, we want to run analytics queries on those events to count how many times a user logs in to better tailor their experience.
A. The trivial solution: synchronous insert
The trivial solution is to synchronously insert these events directly in the database. A simple implementation would mean that each event fired results in a single insert to the database. This comes with 2 main drawbacks:
- Every API call that produces an event becomes slower. I.e. the /login endpoint needs to insert a record in the database
- The database is now hit with a very high amount of insert queries
With our most basic need of 2 event types, we were looking at about 200 to 500 events per second. I concluded this solution would not be scalable. To make it so, 2 things would be necessary: (1) make the event firing mechanism asynchronous and (2) bulk events together before insertion.
B. The serverless asynchronous solution
A second solution is to use a Pub/Sub push subscription to trigger an HTTP endpoint when a message comes in. This would've been easy in my case because we already have a worker-style autoscaled App Engine service that could've hosted this. However, this only solves the 1st problem of the trivial solution; the events still come in one at a time to the HTTP service.
Although it's possible to implement some sort of bulking mechanism in a push endpoint, it's much easier to have a worker pull many messages at once instead.
C. The serverless, fully-managed Dataflow solution
This led me to implement a complete streaming pipeline using GCP's streaming service: Dataflow. Spoiler: this was way overkill and led to weird bugs with DLT (data load tool). If you're curious, I've open-sourced that code too.
This solved both issues of the trivial solution, but proved pretty expensive and hard to debug and monitor.
D. An autoscaled asynchronous pull worker
Disclaimer: I had never considered standalone machines from cloud providers (AWS EC2, GCP Compute Engine) to be a viable solution to my cloud problems. In my head, they seemed like outdated, manually provisioned services that could instead be replaced by managed services.
But here I was, with a need to have a continuously running worker. I decided to bite the bullet and try my luck with GCP Compute Engine. What I realized to my surprise, is that by using instance templates and instance groups, you can easily set up a cluster of workers that will autoscale.
The code is simple: run a loop forever that pulls messages from a Pub/Sub subscription, bulk the messages together, and then insert them in the database. Repeat.
Then deploy that code as an instance group that auto-scales based on the need to process messages.
Code walkthrough
The complete source code is available here.
Summarily, the code is comprised of 2 main parts:
- The pulling and batching logic to accumulate and group messages from Pub/Sub based on their destination table
- The load logic to infer the schema and bulk insert the records into the database. This part leverages DLT for destination compatibility and schema inference
Main loop
By using this micro-batch architecture, we strive to maintain a balance of database insert efficiency (by writing multiple records at a time) with near real-time insertion (by keeping the window size around 5 seconds).
pipeline = dlt.pipeline(
pipeline_name="pubsub_dlt",
destination=DESTINATION_NAME,
dataset_name=DATASET_NAME,
)
pull = StreamingPull(PUBSUB_INPUT_SUBCRIPTION)
pull.start()
try:
while pull.is_running:
bundle = pull.bundle(timeout=WINDOW_SIZE_SECS)
if len(bundle):
load_info = pipeline.run(bundle.dlt_source())
bundle.ack_bundle()
# pretty print the information on data that was loaded
print(load_info)
else:
print(f"No messages received in the last {WINDOW_SIZE_SECS} seconds")
finally:
pull.stop()
How to deploy
The GitHub repo explains how to deploy the project as an instance group.
Database concerns
Using DLT has the major advantage of inferring the schema of your JSON data automatically. This also comes with some caveats:
- The output schema of these analytics tables might change based on events
- If your events have a lot of possible properties, the resulting tables could become very wide (lots of columns) which is not something desirable in an OLTP database
Given these caveats, I make sure that all events fired by our app are fully typed and
limited in scope. Moreover, using the table_name_data_key configuration of the code I
wrote, it's possible to separate different events with different schemas into different
tables.
See this README section for an example of application code and the resulting table.
Performance and cost
After running this code and doing backfills for a couple of weeks, I was able to benchmark the overall efficiency and cost of this solution.
Throughput capacity
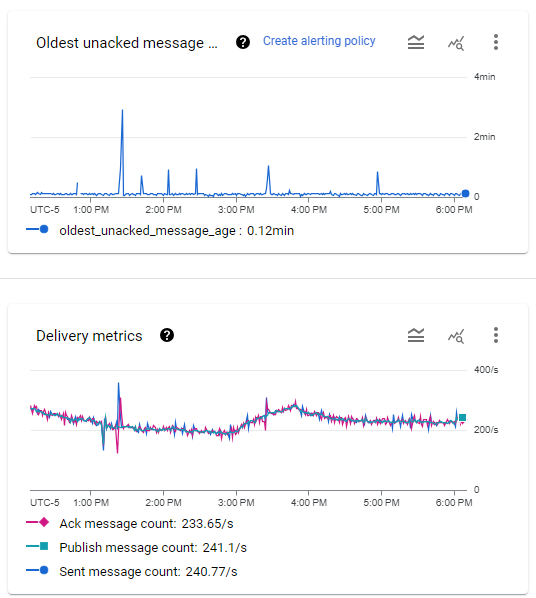
The Pub/Sub subscription metrics. Message throughput ranges between 200 and 300 per second, while the oldest message is usually between 5 and 8 seconds with occasional spikes.
I am running a preemptible (SPOT) instance group of n1-standard-1 machines that auto-scales between 2 and 10 instances. In normal operation, a single worker can handle our load easily. However, because of the preemptible nature of the instances, I set the minimum number to 2 to avoid periods where no worker is running.
Maximum capacity
When deploying the solution with a backlog of messages to process (15 hours worth of messages), 10 instances were spawned and cleared the backlog in about 25 minutes.
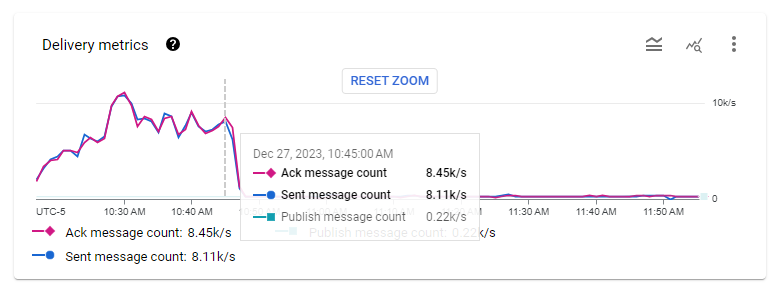
The Pub/Sub subscription throughput metrics when a 15-hour backlog was cleared. The instance group gradually reached 10 instances at about 10:30AM, then cleared the backlog by 10:50AM.
Between 7000 and 10000 messages per second were processed on average by these 10 instances, resulting in a minimum throughput capacity of 700 messages/s per worker.
Cost
Using n1-standard-1 spot machines, this cluster costs $8.03/mth per active machine. With a minimum cluster size of 2, this means $16.06 per month.
Conclusion
Using more "primitive" GCP services around Compute Engine provides a straightforward and cost-effective way to process a high throughput of Pub/Sub messages from a pull subscription.